bulk_upsert APIを利用して、任意のCSVファイルをコンテンツにインポートする
bulk_upsertは、複数のコンテンツを一括で更新するためのAPIオペレーションです。
これを利用して、任意のフォーマットのCSVファイルをコンテンツにインポートする方法を説明します。
前提条件
CSVファイルは、次のような前提条件に基づいてインポートするものとします。
- 対象のCSVファイルはKurocoFilesに手動でアップロードする
- バッチ処理で毎日0:00にインポート処理を実行する
- 前日0:00からバッチ実行開始までの間にファイルの更新があった場合にインポート処理を実行する
- 対象のコンテンツが既に存在する場合は更新、存在しない場合は新規追加する
- 対象のCSVファイルはUTF-8の文字コードで保存されている
CSVファイルを用意する
まずはインポート対象のCSVデータを用意します。今回は、以下のようなモバイル端末のリストを利用します。
| item_number | item_name | category | description | status | item_color | release_date | is_public |
|---|---|---|---|---|---|---|---|
| 00000001 | SmartPhone | SP | スマートフォン | 1 | black,white,red,blue | 2020/12/10 | TRUE |
| 00000002 | SmartPhone Lite | SP | 廉価版スマートフォン | 1 | black,white | 2021/12/10 | TRUE |
| 00000003 | Tablet | TB | タブレット | 0 | silver | 2020/1/15 | FALSE |
| 00000004 | Tablet 2 | TB | タブレット (第2世代) | 1 | silver | 2022/1/15 | TRUE |
各カラムの項目定義は以下の通りです。
| 項目名 | 項目内容 | 値 |
|---|---|---|
| item_number | 製品番号 | 製品毎に一意となる8桁の数値 |
| item_name | 製品名 | 任意のテキスト |
| category | 製品種別 | テキスト SP: スマートフォン TB: タブレット |
| description | 製品概要 | 任意のテキスト |
| status | 販売状況 | 数値 0: 販売終了 1: 販売中 |
| item_color | 製品カラー | テキスト (カンマ区切りで複数設定可) black: 黒 white: 白 silver: シルバー red: 赤 blue: 青 |
| release_date | 発売日 | 日付 (yyyy/mm/dd) |
| is_public | 公開/非公開 | テキスト TRUE: 公開 FALSE: 非公開 |
コンテンツ定義を設定する
1. 項目を設計する
CSVの各行をコンテンツとしてインポートできるようにするため、まずはコンテンツ定義の項目設計をします。
対応するデフォルト項目が存在する場合はデフォルト項目を使います。
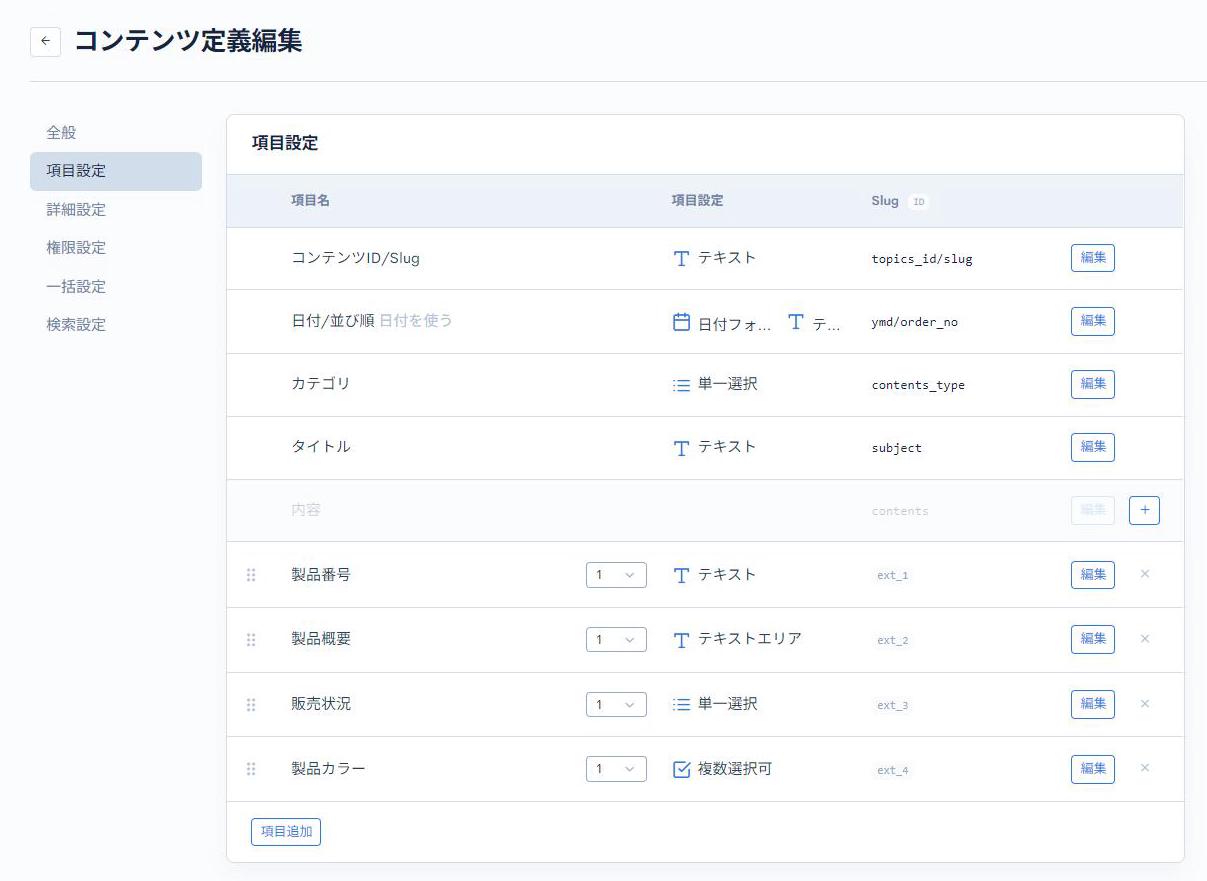
それ以外のものは拡張項目にマッピングし、CSVの項目と同名のSlugを設定します。
| CSV項目名 | Kuroco項目名(管理画面) | Kuroco項目名(API) | 項目形式 | 説明 |
|---|---|---|---|---|
| item_number | Slug | slug | - | bulk_upsertエンドポイントへのリクエスト時に使用します。 オリジナルの項目は数値形式ですが、Slugにはテキスト形式の値を設定する必要があるため、次のように接頭辞を付与します。 ITEM-%%item_number%% |
| item_name | タイトル | subject | - | |
| category | カテゴリ | contents_type | - | |
| release_date | 日付 | ymd | - | |
| is_public | 公開設定 | open_flg | - | |
| item_number | 拡張項目1 | item_number | テキスト | Slugにも同一の項目をマッピングしていますが、ここでは接頭辞のないオリジナルの値を設定します。 |
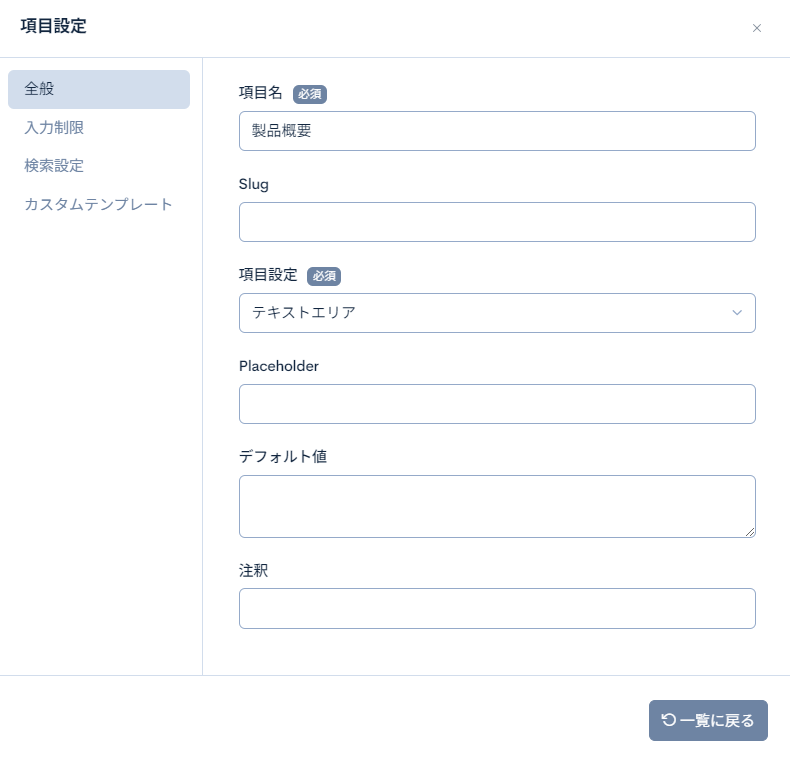
| description | 拡張項目2 | description | テキストエリア | |
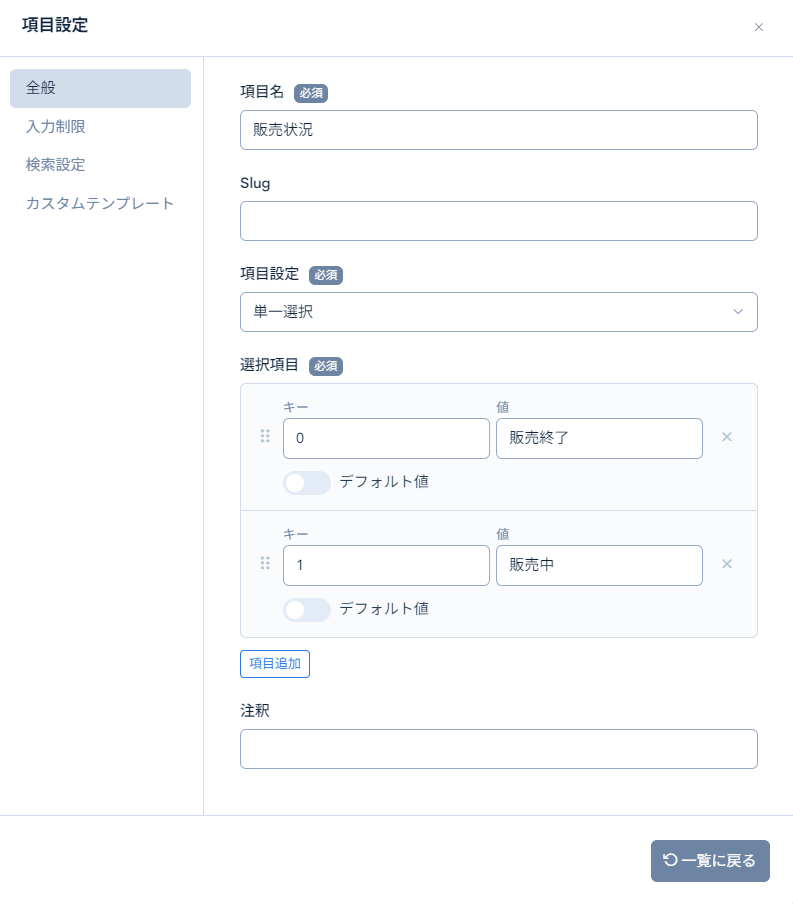
| status | 拡張項目3 | status | 単一選択 | 下記の選択肢を設定します。0::販売終了1::販売中 |
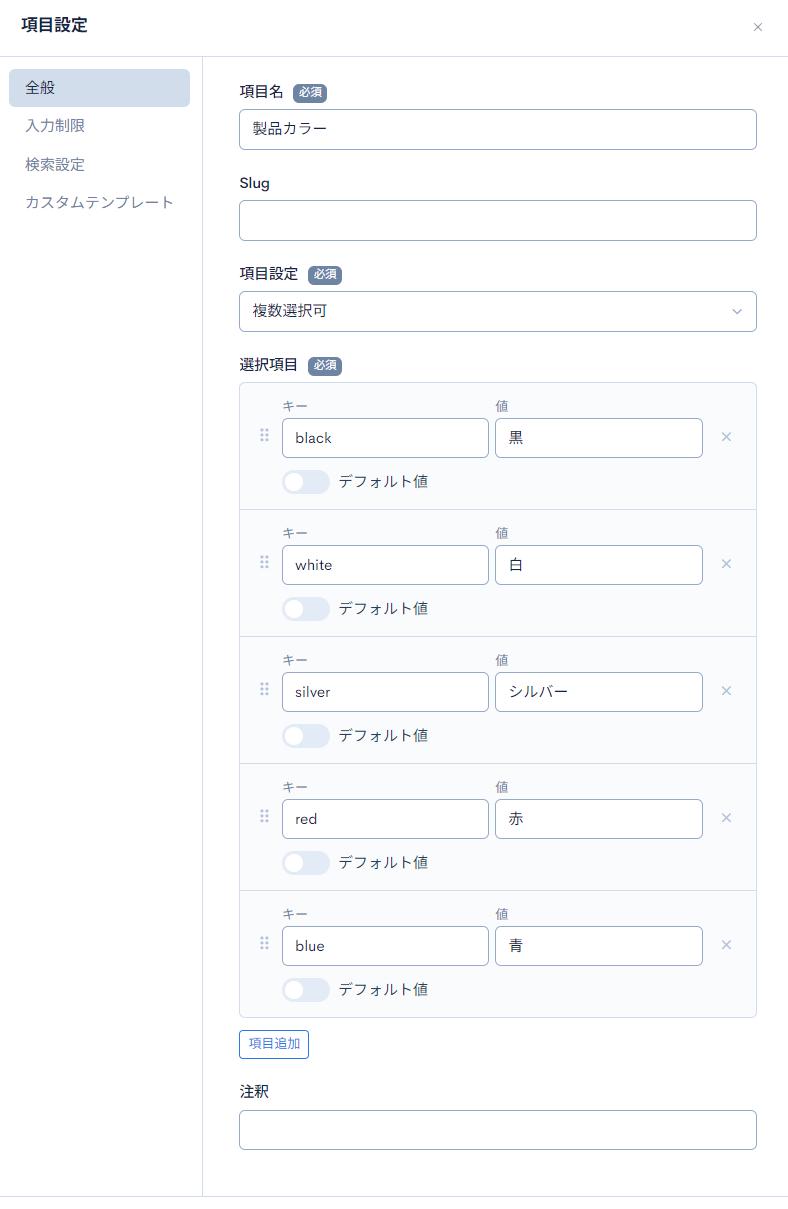
| item_color | 拡張項目4 | item_color | 複数選択可 | 下記の選択肢を設定します。black::黒white::白silver::シルバーred::赤blue::青 |
2. コンテンツ定義を新規作成する
各項目の設計が終わったら、CSVのインポート先となるコンテンツ定義を作成します。
詳しい作成方法については、コンテンツ定義を作成する
を参照ください。
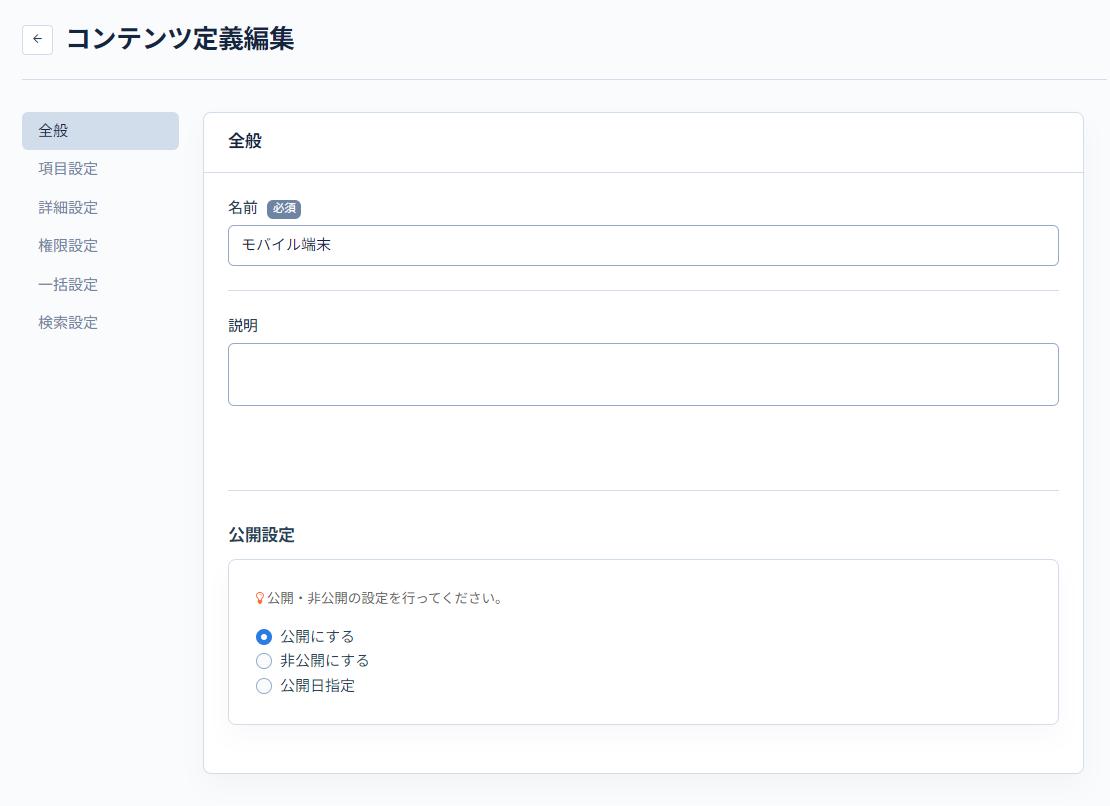
まずは次のように設定をします。その他の項目については、デフォルト設定のままとします。
| 設定項目名 | 値 | 説明 |
|---|---|---|
| 名前 | モバイル端末 | |
| 更新履歴を残さない | 有効にする | 更新履歴を残さない代わりに、コンテンツの取得・更新時のパフォーマンスを向上させることができます。 今回のように日次でデータを更新する必要がある場合は、設定することを推奨します。 |
次に、「1. 項目を設計する」で定義した通りに拡張項目を設定します。
以上の設定が完了したら、[追加する]ボタンをクリックし、コンテンツ定義を新規追加します。
3. カテゴリを作成する
最後にコンテンツのカテゴリを作成し、category項目をマッピングできるようにします。
詳しい設定方法については、コンテンツカテゴリ を参照ください。
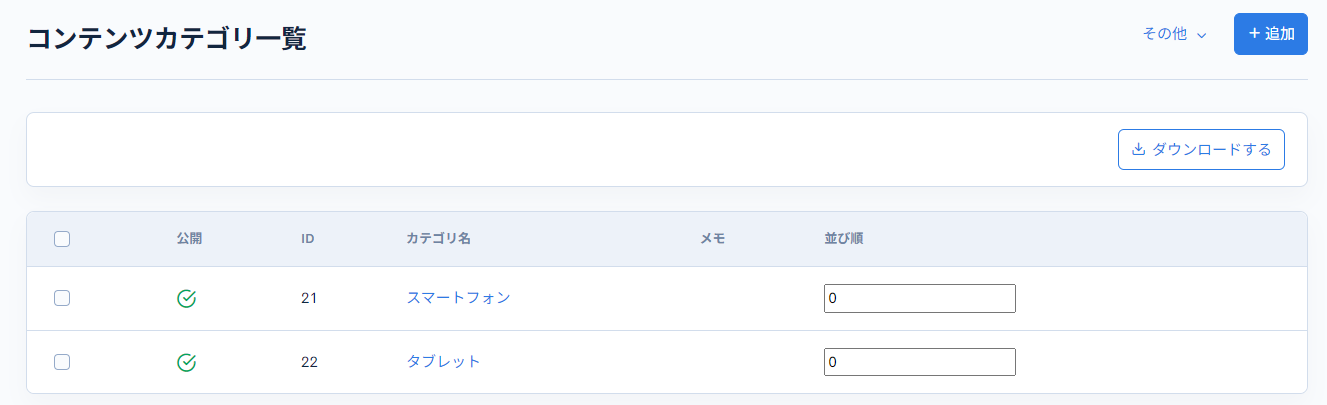
| カテゴリID | カテゴリ名 | 拡張項目 01 |
|---|---|---|
| 21 (自動採番) | スマートフォン | SP |
| 22 (自動採番) | タブレット | TB |
カテゴリIDは新規作成時に自動採番されるため、自身の環境で設定された値に置き換えてください。
拡張項目には、インポート元CSVのカテゴリ値を設定しておきます。
バックエンド処理の実行メンバーを設定する
バックエンド処理の実行者となるメンバーを設定します。ここで設定したメンバーIDは、後ほどバッチ処理を記述する際に利用します。
メンバーを新規作成する
メンバー編集の画面にアクセスし、バックエンド処理の実行者となるメンバーを新規作成します。
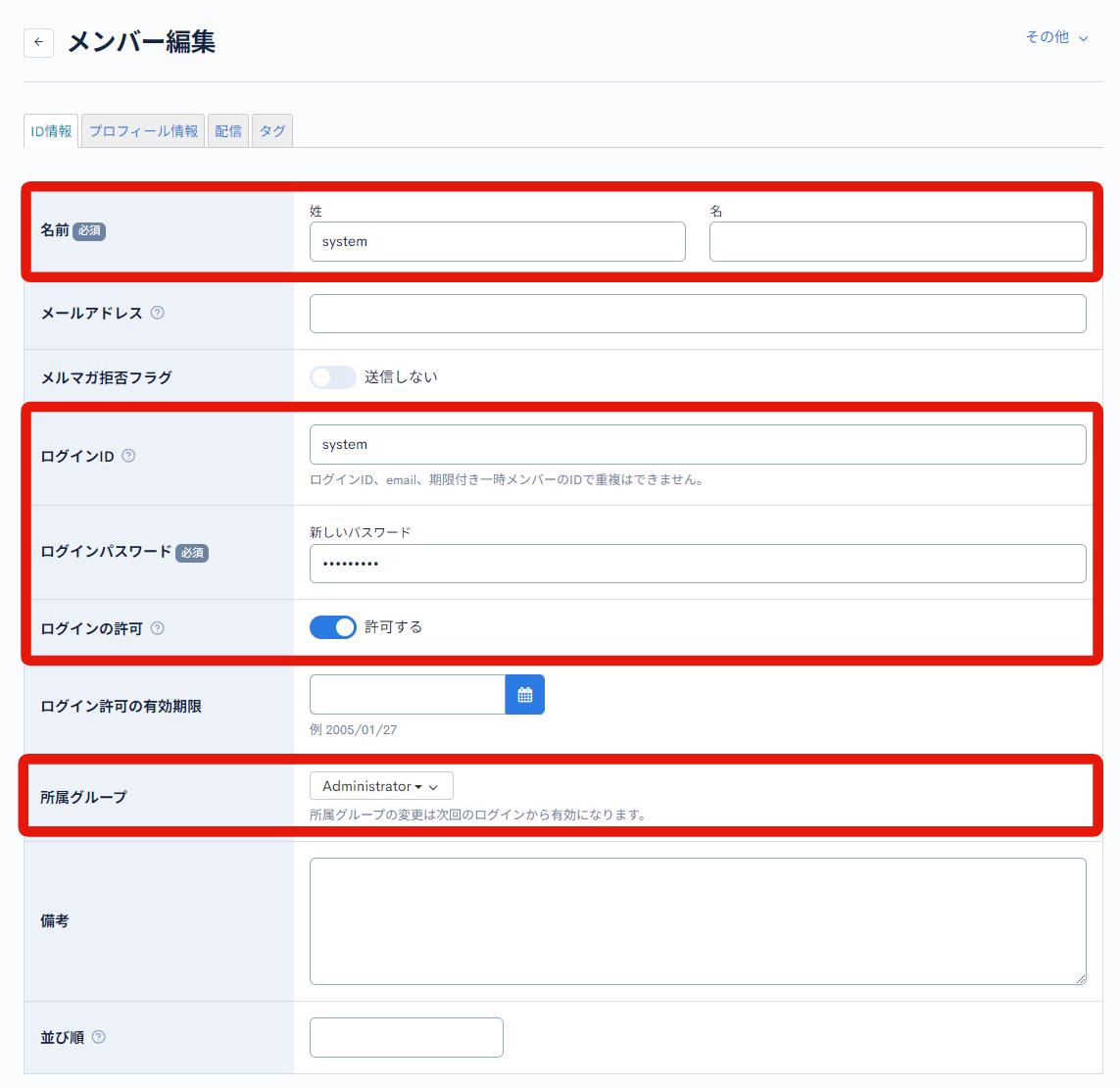
| 項目名 | 値 | 説明 |
|---|---|---|
| 名前 | system | バックエンド用途であることを判別しやすい値を設定します。 |
| ログインID | system | バックエンド用途であることを判別しやすい値を設定します。 |
| パスワード | (パスワード値) | 他で利用していない強固なパスワードを設定してください。 |
| グループ | Admin | ユーザー種別が「スーパーユーザー」のグループを設定します。今回は、サイト作成時にデフォルトで存在するグループ(グループID: 1)を利用します。 |
定数を設定する
定数 画面にアクセスし、バッチ処理から参照するための定数を設定します。
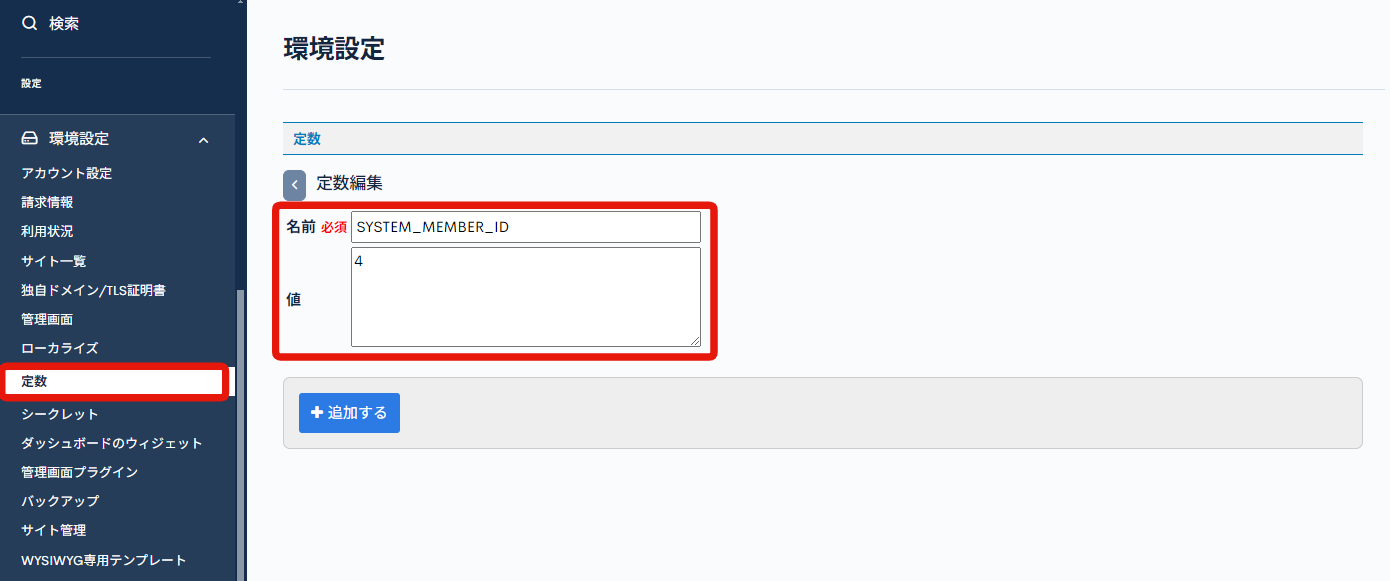
| 項目名 | 値 | 説明 |
|---|---|---|
| 名前 | SYSTEM_MEMBER_ID | |
| 値 | 4 | 先ほど新規作成したメンバーのIDを設定します。IDは自動採番されるため、自身の環境で設定された値に置き換えてください。 |
APIを設定する
APIを新規作成する
API画面にアクセスし、バックエンド処理用のエンドポイントを設定するためのAPIを新規作成します。
同一のAPIに用途の異なるエンドポイント(フロントエンド用・バックエンド用など)を混在させると、認証の設定が複雑化します。 セキュリティ上のリスクが高まる可能性があるため、API設定は用途別に分けることを推奨します。

| 項目名 | 値 | 説明 |
|---|---|---|
| タイトル | Internal API | バックエンド用途であることを判別しやすい値を設定します。 |
| 版 | 1.0 | |
| ディスクリプション | Internal API for Backend Process |
APIの作成が完了したら、[セキュリティ] をクリックし、「動的アクセストークン」を選択して保存します。
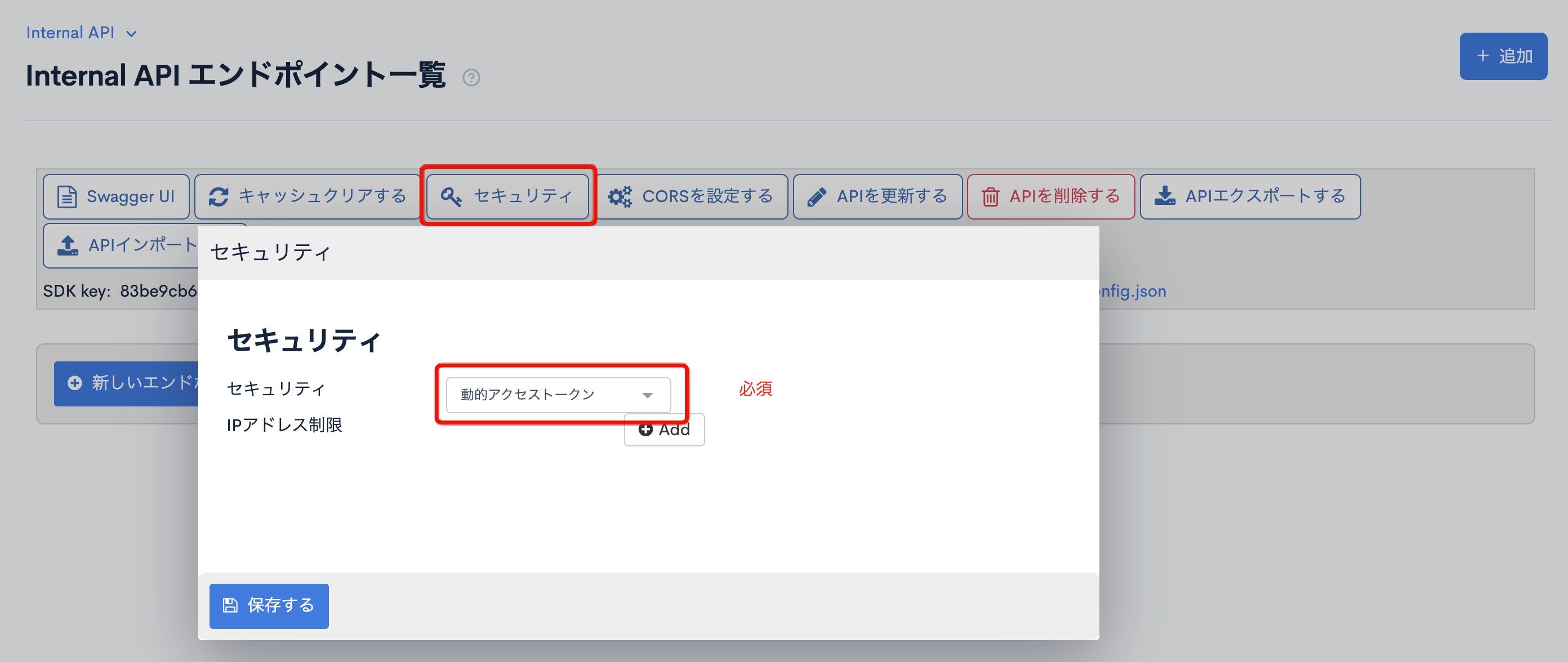
APIエンドポイントを追加する
[新しいエンドポイントの追加] ボタンをクリックし、先ほど設定したAPIにbulk_upsertのエンドポイントを追加します。
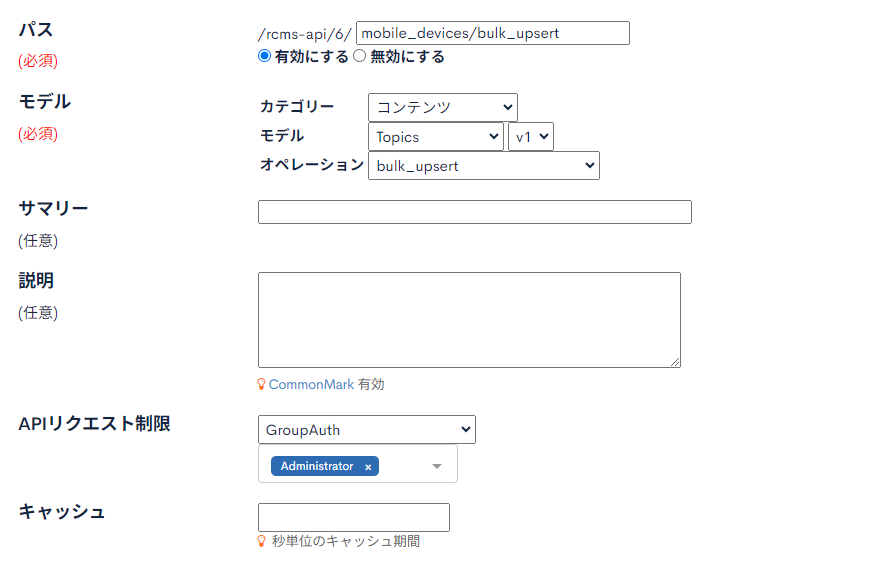
| 項目名 | 値 | 説明 |
|---|---|---|
| パス | mobile_devices/bulk_upsert | |
| モデル | カテゴリー: コンテンツ モデル: Topics (v1) オペレーション: bulk_upsert | |
| APIリクエスト制限 | GroupAuth (Admin) | メンバーを新規作成する で作成したメンバーが所属するグループを設定します。 |
基本設定と詳細設定には下記の値を設定します。
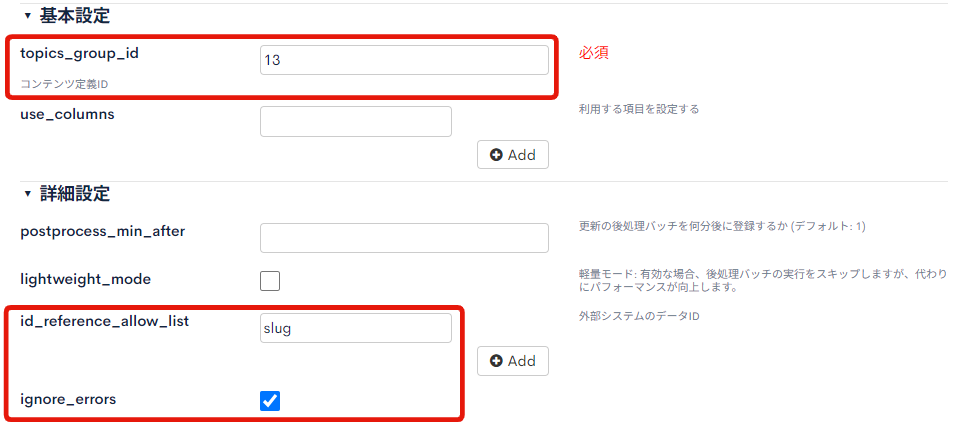
| パラメータ名 | 値 | 説明 |
|---|---|---|
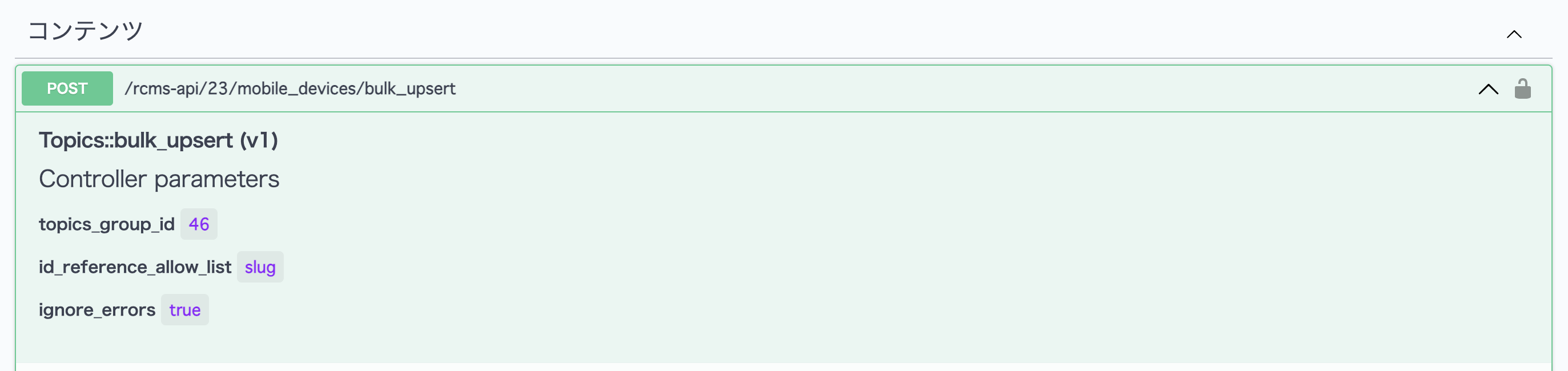
| topics_group_id | 13 | 更新対象となるコンテンツ定義のIDです。事前に作成したコンテンツ定義「モバイル端末」に採番されたIDを設定します。 |
| id_reference_allow_list | slug | コンテンツ更新時のキーとして指定可能な項目を設定します。詳しくは後述します。 |
| ignore_errors | true | バリデーションエラーが発生した行を無視し、有効なコンテンツのみを追加・更新することができます。 |
id_reference_allow_listパラメータについて
bulk_upsert APIで既存のコンテンツを更新する際には、対象のコンテンツを特定するためのキーとなるtopics_idを指定する必要があります。通常であれば、以下のようにKurocoで自動採番された数値を指定します。
{
"topics_id": 1,
"slug": "ITEM-00000001",
"subject": "Smartphone",
...
}
ここで問題になるのは、更新対象となるtopics_idをどのように特定するかです。
他の項目についてはCSVファイルから値を変換できますが、topics_idはKurocoでのみ保持しているデータです。この値を特定するためには、あらかじめlist APIを呼び出して、既存のコンテンツを取得しておく処理を行う必要があります。しかし、これを実装することには以下のような問題があります。
- プログラムが複雑になる
- 処理時間が増加する
id_reference_allow_listは、上記を解決するために用意されたパラメータです。設定すると、topics_idの代わりに任意の項目をキーとしてコンテンツを追加・更新できます。例えば今回のようにslugを設定した場合、次のようなリクエストが指定可能になります。
{
"topics_id": "slug",
"slug": "ITEM-00000001",
"subject": "Updated Title",
...
}
上記のデータを送信した場合、slug = "ITEM-00000001"のコンテンツが既に存在すれば更新し、存在しなければ新規追加する挙動になります。これによって、Kuroco側で採番されたtopics_idを考慮せずに、元データのIDのみを利用してコンテンツを追加できるようになります。
バッチ処理を実装する
ここまでに設定した内容を利用して、日次でインポートを行うバッチ処理を実装します。
まずはバッチ処理編集画面にアクセスし、次の内容を入力します。
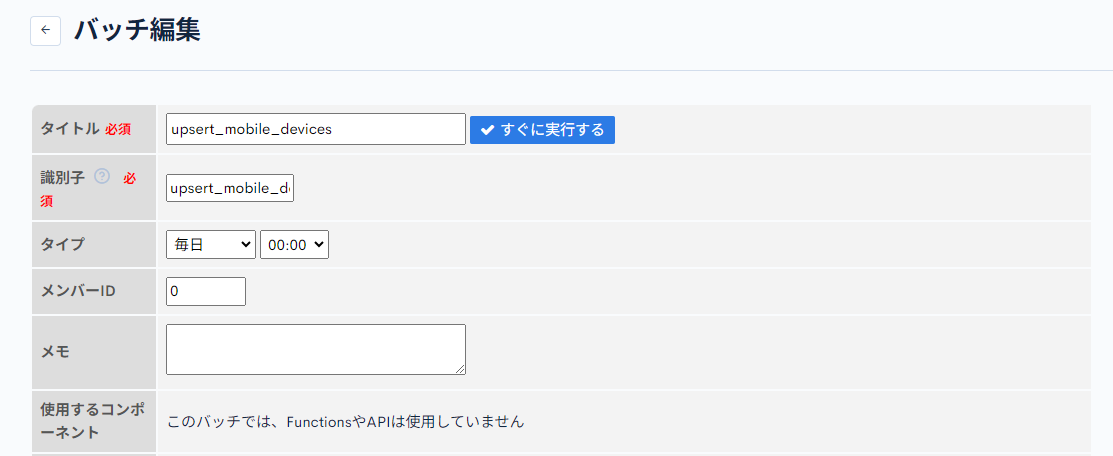
| 項目名 | 値 |
|---|---|
| タイトル | upsert_mobile_devices |
| 識別子 | upsert_mobile_devices |
| タイプ | 毎日/00:00 |
完了したら「実行内容」のエディタ上に次の処理を入力し、新規追加します。
{*
前処理
*}
{* 定数に設定したメンバーidで認証 *}
{login member_id=$smarty.const.SYSTEM_MEMBER_ID overwrite=true}
{* CSVファイルが配置されているかを確認 *}
{assign var='uploaded_csv_path' value='/files/ltd/bulk_upsert/mobile_devices.csv'}
{if !$uploaded_csv_path|rcms_file_exists}
{logger msg1='upsert_mobile_devices' msg2='CSV file is not found'}
{return}
{/if}
{* CSVファイルの更新日時を確認 *}
{assign var='csv_updated_at' value=$uploaded_csv_path|rcms_file_mtime}
{if $csv_updated_at < '-1 day 0:00:00'|strtotime}
{logger msg1='upsert_mobile_devices' msg2='CSV file is not updated'}
{return}
{/if}
{* %% bulk_upsert %% *}
続いて、上記コードのコメント箇所{* %% bulk_upsert %% *}を、実際のコンテンツ更新処理に置き換えます。
まずはSwagger UI画面を開き、先ほど作成したエンドポイント mobile_devices/bulk_upsert を選択してください。
[Request body] -> [Schema] をクリックし、 bulk_upsertエンドポイントが受け取れるリクエスト ボディの定義を確認します。
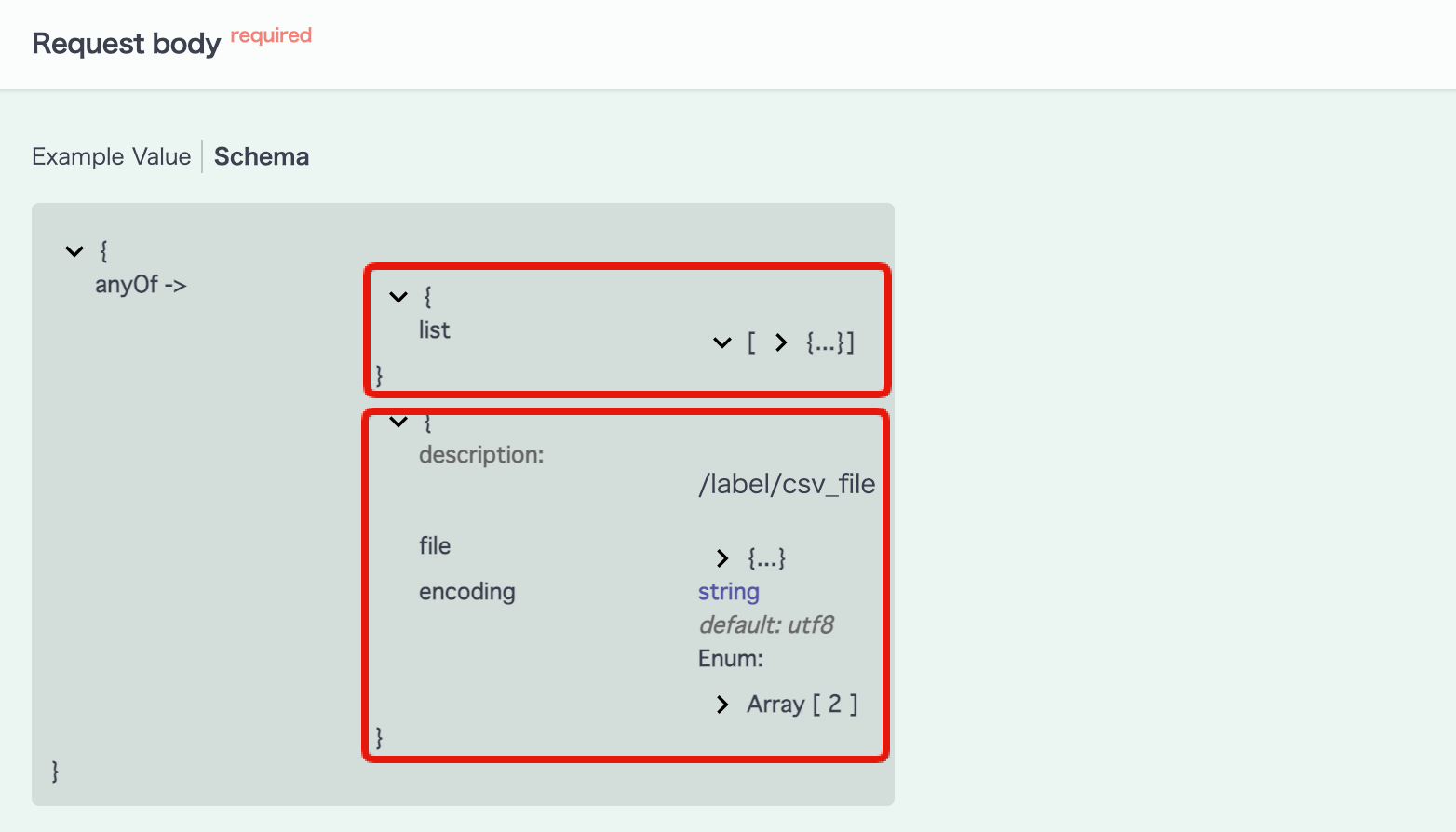
bulk_upsert APIは、以下2種類の形式でリクエスト ボディを指定できます。 今回はJSON形式を利用して処理を進めて行きます。
| 形式 | リクエスト ボディ |
|---|---|
| JSON | {"list": [{...}]} |
| CSVファイル | {"file": {...}, "encoding": "..."} |
JSON形式で更新する場合
Request bodyのスキーマからlistプロパティを展開すると、各項目の詳細な定義を確認できます。
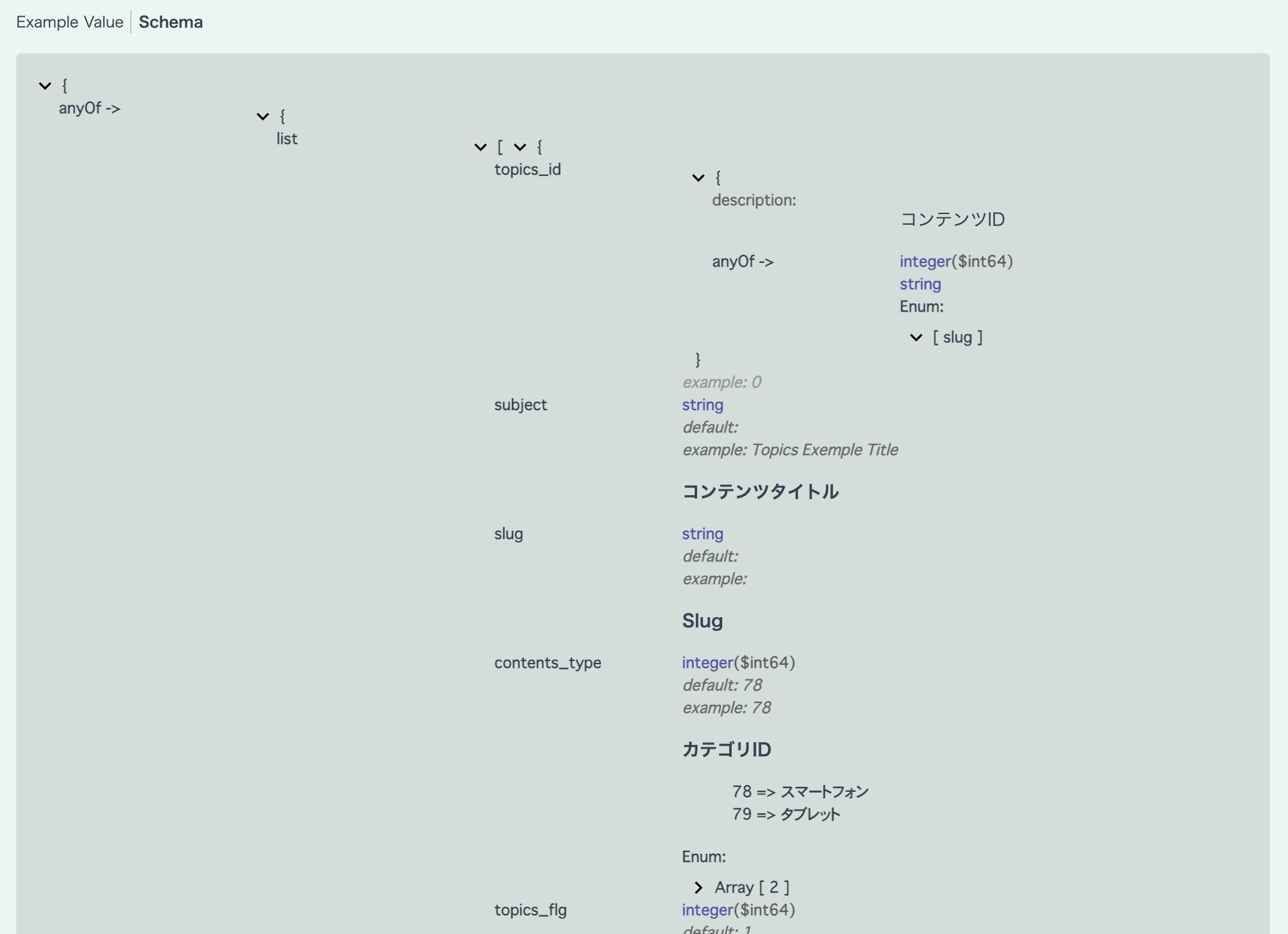
上記のスキーマと、今回の更新対象となる項目を照らし合わせると、次のようなリクエスト ボディを指定すればいいことがわかります。
{
"list": [
{
"topics_id": "slug",
"slug": "ITEM-00000001",
"subject": "SmartPhone",
"contents_type": 78,
"open_flg": 1,
"ymd": "2020-12-10",
"item_number": "00000001",
"description": "スマートフォン",
"status": "1",
"item_color": ["black", "white", "red", "blue"]
},
{
"topics_id": "slug",
"slug": "ITEM-00000001",
// ...
},
// ...
]
}
エンドポイントに渡すべきリクエスト ボディの形式がわかったため、バッチ処理を実装します。先ほど作成したバッチ処理に以下のコードを追記し、[更新]ボタンをクリックしてください。
{*
必要な変数の初期化
*}
{* bulk_upsertエンドポイントに渡すjson body ({"list": []}) *}
{assign_array var='bulk_upsert_body' values=''}
{assign_array var='bulk_upsert_body.list' values=''}
{assign_array var='csv_header' values=''}{* CSVヘッダー ([]) *}
{assign var='chunk_unit' value=1000}{* 分割アップロードする単位 *}
{*
処理対象CSVの総行数を事前に取得
*}
{assign var='last_index' value=-1}
{read_file name='uploaded_csv' row='csv_row' type='csv' path=$uploaded_csv_path}
{assign var='last_index' value=$last_index+1}
{logger msg1="last_index取得処理" msg2=$last_index}
{/read_file}
{*
更新処理
*}
{* 処理中の行を示すインデックス *}
{assign var='i' value=0}
{* CSVファイルの読み取り *}
{read_file name='uploaded_csv' row='csv_row' type='csv' path=$uploaded_csv_path}
{if !$csv_row|@is_array}
{logger msg1='upsert_mobile_devices' msg2='Invalid csv row' msg3=$csv_row}
{elseif $i === 0}
{* CSVヘッダーの取得 *}
{assign var='csv_header' value=$csv_row}
{$csv_header|@rcms_json_encode}
{logger msg1="CSVヘッダーの取得" msg2=$csv_row}
{else}
{logger msg1="CSV内容の取得"}
{* CSV行の変換 *}
{assign_array var='topics' values=''}
{assign var='topics.topics_id' value='slug'}{* slugをキーとして追加/更新 *}
{foreach from=$csv_row key='k' item='v'}
{assign var='col_name' value=$csv_header[$k]}{* CSVの項目名を取得 *}
{if $col_name == 'item_number'}
{* 製品番号 *}
{assign var='topics.slug' value="ITEM-`$v`"}
{assign var='topics.item_number' value=$v}
{elseif $col_name == 'item_name'}
{* 製品名 *}
{assign var='topics.subject' value=$v}
{elseif $col_name == 'category'}
{* カテゴリ *}
{if $v == 'SP'}
{assign var='topics.contents_type' value=78}
{elseif $v == 'TB'}
{assign var='topics.contents_type' value=79}
{/if}
{elseif $col_name == 'item_color'}
{* カラー *}
{assign var='topics.item_color' value=','|explode:$v}
{elseif $col_name == 'release_date'}
{* 発売日 *}
{strtodate var='topics.ymd' format='Y-m-d' timestamp=$v}
{elseif $col_name == 'is_public'}
{* 公開/非公開 *}
{if $v == 'TRUE'}
{assign var='topics.open_flg' value=1}
{else}
{assign var='topics.open_flg' value=0}
{/if}
{else}
{* その他 *}
{assign var="topics.`$col_name`" value=$v}
{/if}
{/foreach}
{* JSON bodyに追記 ({"list": [..., {...}]}) *}
{assign var='bulk_upsert_body.list.' value=$topics}
{/if}
{* $chunk_unitで定義した件数毎に分割して更新 *}
{if $bulk_upsert_body|@count === $chunk_unit ||
($i === $last_index && $bulk_upsert_body|@count > 0)}
{* bulk_upsertエンドポイントへのリクエスト (_async=trueパラメータを付与し、バッチ処理で実行) *}
{api_internal
var='bulk_upsert_response'
status_var='bulk_upsert_status'
endpoint='/rcms-api/23/mobile_devices/bulk_upsert?_async=true'
method='POST'
queries=$bulk_upsert_body
member_id=$smarty.session.member_id}
{* 失敗した場合ログに出力 *}
{if !$bulk_upsert_status || $bulk_upsert_response.errors}
{logger msg1='upsert_mobile_devices' msg2='Request failed' msg3="index: `$i`" msg4=$bulk_upsert_response}
{/if}
{* JSON bodyの初期化 ({"list": []}) *}
{assign_array var='bulk_upsert_body.list' values=''}
{/if}
{logger msg1=$i msg2=$last_index msg3=$topics msg4=$csv_row}
{assign var='i' value=$i+1}
{/read_file}
/rcms-api/23/mobile_devices/bulk_upsertの部分はご自身のエンドポイントのURLを使用してください。
{assign var='topics.contents_type' value=78}、{assign var='topics.contents_type' value=79}の部分は自身のカテゴリIDを使用してください。
処理の内容について補足します。
CSVファイルの読み取りについて
read_fileは、テキストデータを1行ごとに読み取るためのプラグインです。typeパラメータにcsvを指定すると、CSVファイルの読み取りに利用できます。
read_fileで読み取れる文字コードはUTF-8のみです。
{read_file name='uploaded_csv' row='csv_row' type='csv' path=$uploaded_csv_path}
{* ... *}
{/read_file}
CSVの行データはrowパラメータで指定した変数名$csv_rowにアサインされます。{read_file}{/read_file}のブロック内に次の処理を記述することで、データの内容を確認できます。
{$csv_row|@rcms_json_encode}
出力されるのは以下のような配列データです。これらの値を項目定義に基づいて変換することで、リクエスト ボディを生成しています。
["00000001", "SmartPhone", "SP", "スマートフォン", "1", "black,white,red,blue", "2020/12/10", "TRUE"]
コンテンツの追加・更新について
コンテンツの追加・更新をするbulk_upsertエンドポイントの呼び出しには、api_internalプラグインを利用します。詳しい利用方法については、オリジナル処理からKurocoのAPIを呼び出せますか?を参照ください。
{api_internal
var='bulk_upsert_response'
status_var='bulk_upsert_status'
endpoint='/rcms-api/23/mobile_devices/bulk_upsert?_async=true'
method='POST'
queries=$bulk_upsert_body
member_id=$smarty.session.member_id}
エンドポイントのパスには、APIの処理を非同期で実行するための_async=trueパラメータを付与しています。
通常、エンドポイントの呼び出しは同期的に行われます。リクエストの送信後は処理が完了するまで待つ必要があります。しかし、bulk_upsert APIは大量のコンテンツを一括で扱う都合上、CSVのデータ数によっては処理の完了までに時間が掛かり、タイムアウトが発生します。
_async=trueパラメータを利用すると、リクエスト時には追加・更新処理を実行せず、バッチ処理の登録のみを行い即時にレスポンスを返します。呼び出したAPIの処理は呼び出し元とは別のプロセス上で実行されるため、タイムアウトの問題を回避できます。更新対象データの件数が多い場合に指定してください。
動作の確認をする
以上で、設定は完了したので動作の確認をします。
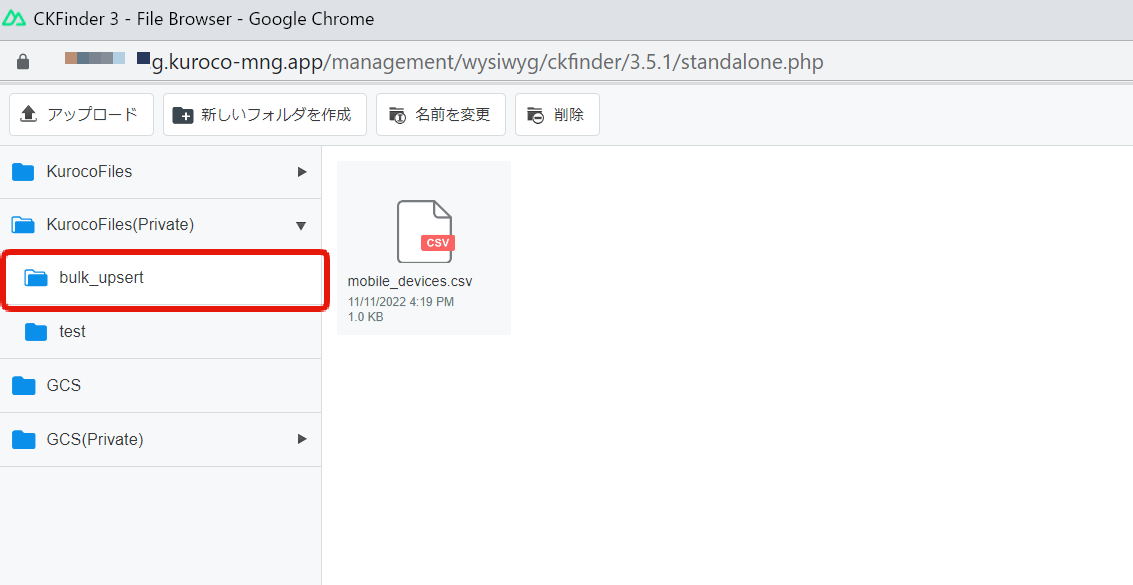
まずはCSVファイル(mobile_devices.csv)をバッチ処理で指定したディレクトリ(/ltd/bulk_upsert)に設置します。
KurocoFiles(Private)のフォルダがltdになるので配下にbulk_upsertのフォルダを作成し、CSVファイルを設置ください。
次に、先ほど作成したバッチ処理にアクセスし、[すぐに実行する]をクリックします。
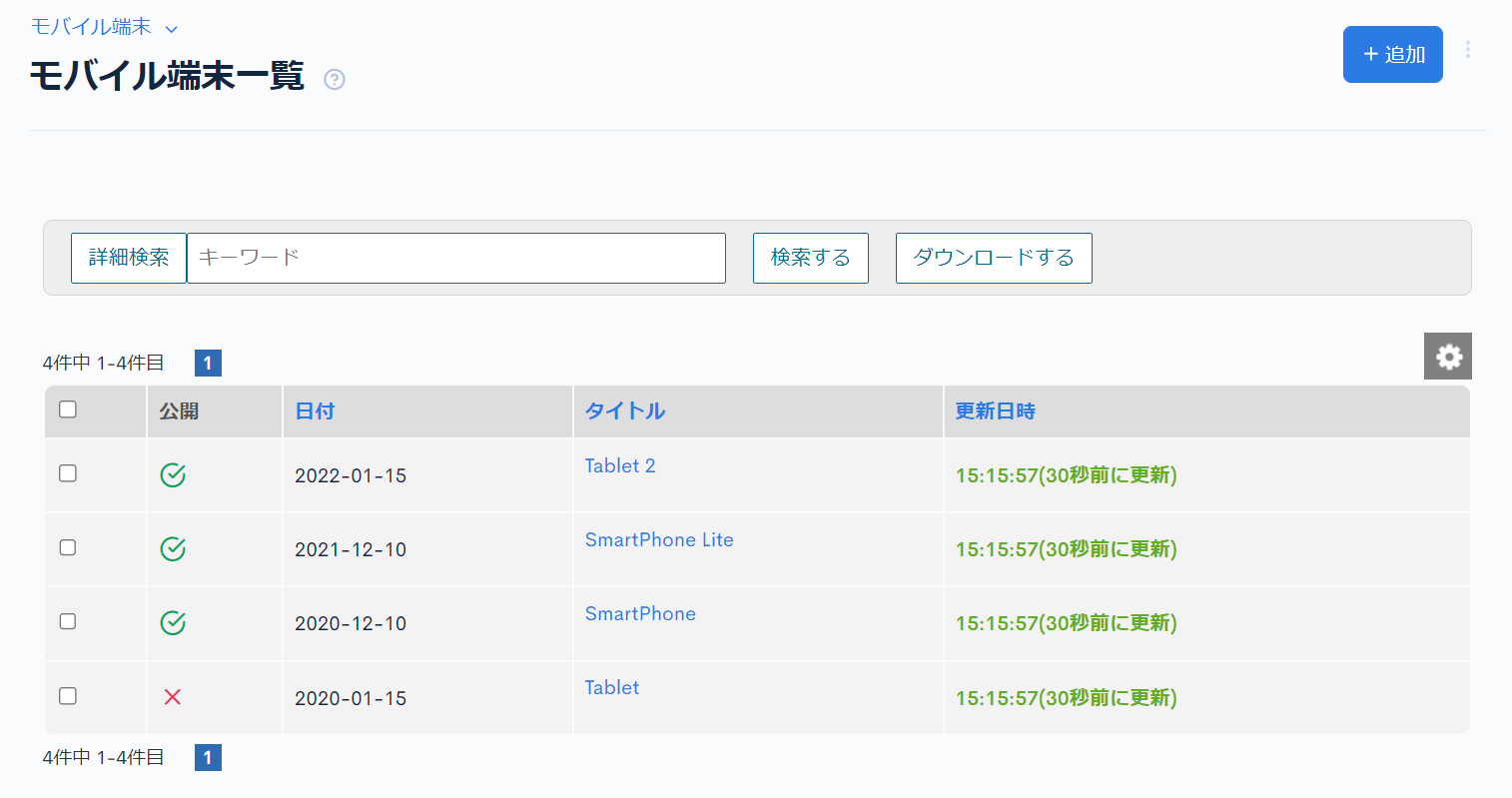
「モバイル端末」のコンテンツ一覧を確認すると、CSVからコンテンツが登録されていることが分かります。
以上で動作の確認が完了です。
関連ドキュメント
サポート
お探しのページは見つかりましたか?解決しない場合は、問い合わせフォームからお問い合わせいただくか、Slackコミュニティにご参加ください。